
Lettres capitales et systèmes de classification
Auteur(s)
Date
Partager
Résumé
Création d’un modèle de classification de tweets basé sur l’utilisation des lettres capitales dans une série de publications.
Auteur(s)
Date
Partager
Résumé
Création d’un modèle de classification de tweets basé sur l’utilisation des lettres capitales dans une série de publications.
L’analyse de la ponctuation et de la forme des lettres (majuscule, capitale et minuscule) constitue un axe intéressant pour mettre au jour des caractéristiques et des marqueurs identiaires sémantiques et linguistiques dans un corpus de texte.
Dans une logique de machine learning, on peut considérer que l’analyse de la forme des lettres, en complément d’une analyse de la ponctuation, de la tonalité ou encore des emojis, peut permettre de faire ressortir des patterns autres que des unités sémantiques, comme un mot ou groupe de mots (ngrams).
Dans certains contextes, on peut également considérer que l’utilisation synchronique de lettres capitales est un marqueur d’une forme de violence ou de colère à un moment donné, tandis qu’une utilisation diachronique renverrait, soit à une violence dans le temps, soit à une stratégie éditoriale spécifique faisant de l’utilisation accrue des lettres capitales un marqueur identitaire et communicationnel.
En nous intéressant à la communication de deux Chefs d’État, en l’occurrence Donald Trump et Emmanuel Macron, sur le réseau social Twitter on peut appréhender toute la fertilité heuristique des analyses de données basée sur la densité de lettres capitales.
tml_macron <- read_csv("https://www.dropbox.com/s/e9b9uzv6qckpyhg/macron.csv?raw=1")
tml_trump <- read_csv("https://www.dropbox.com/s/pwiyxdhl8klixro/trump.csv?raw=1")
join <- rbind(tml_macron,
tml_trump) %>%
group_by(username) %>%
filter(date >= "2018-01-01")Pour ce faire, nous avons récupéré l’ensemble des publications organiques de Donald Trump et d’Emmanuel Macron depuis le 1er janvier 2018.
obs <- join %>%
group_by(username) %>%
summarise(`Nombre d'observations` = n()) %>%
rename(`Chef d'État` = 1)Notre corpus de publications est composé des observations suivantes :
| Chef d’État | Nombre d’observations |
|---|---|
| emmanuelmacron | 3094 |
| realdonaldtrump | 8795 |
À partir de ces données, on peut calculer la densité de lettres capitales dans chacune des publications de Donald Trump et d’Emmanuel Macron.
Afin d’éviter tous biais, nous devons au préalable supprimer les mentions de comptes, ainsi que les URL :
text <- join %>%
rowwise() %>%
select(username, tweet, date) %>%
mutate(text_clean = gsub("@\\S+\\s*", " ", tweet),
text_clean = gsub("http\\S+\\s*", " ", text_clean),
text_clean = gsub("https\\S+\\s", " ", text_clean),
text_clean = gsub("pic.twitter.com/.*", " ", text_clean),
text_clean = gsub(".*pic.twitter.com", " ", text_clean),
nchar = nchar(text_clean),
nspaces = length(strsplit(text_clean, " ")[[1]]),
nchar_count = nchar - nspaces,
text_clean = paste0(tolower(substr(text_clean, 1, 1)), substr(text_clean, 2, nchar)),
text_clean = gsub("[[:punct:] ]", " ", text_clean),
cap_count = str_count(text_clean, "[A-Z]"),
cap_dens = cap_count / nchar_count,
week = round_date(date, unit = "week")) %>%
group_by(username, week) %>%
mutate(cap_dens_weekly = mean(na.omit(cap_dens))) %>%
ungroup() %>%
select(-c(nchar, nspaces)) %>%
filter(nchar_count > 0)
text %>%
ggplot(aes(x = date, y = cap_dens, color = username)) +
geom_jitter() +
theme_minimal() +
labs(color = "Chefs d'État",
x = NULL,
y = "Densité de lettres capitales / tweet") +
theme(legend.position = "bottom")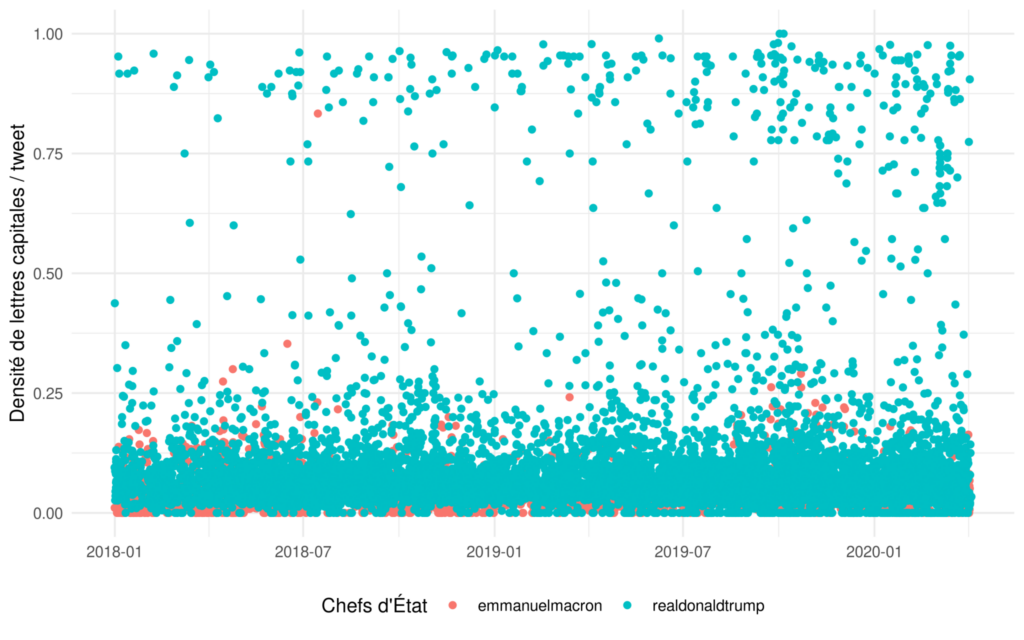
En représentant graphiquement la densité de lettres capitales par publication de chacun des Chefs d’États dans le temps, on remarque qu’au-delà d’un certain seuil (0,35), et à une seule exception près, seules sont présentes les publications de Donald Trump.
Quant à celles d’Emmanuel Macron, pour l’essentiel, elles se situent en deçà du seuil des 0,25.
require(lubridate)
text %>%
mutate(date = floor_date(date, unit = "week")) %>%
group_by(username, date) %>%
mutate(moy = mean(cap_dens)) %>%
distinct(date, .keep_all = T) %>%
ggplot(aes(x = date, y = moy, color = username)) +
geom_line() +
geom_point() +
theme_minimal() +
labs(color = "Chefs d'État",
x = NULL,
y = "Moyenne hebdomadaire de lettres capitales") +
theme(legend.position = "bottom")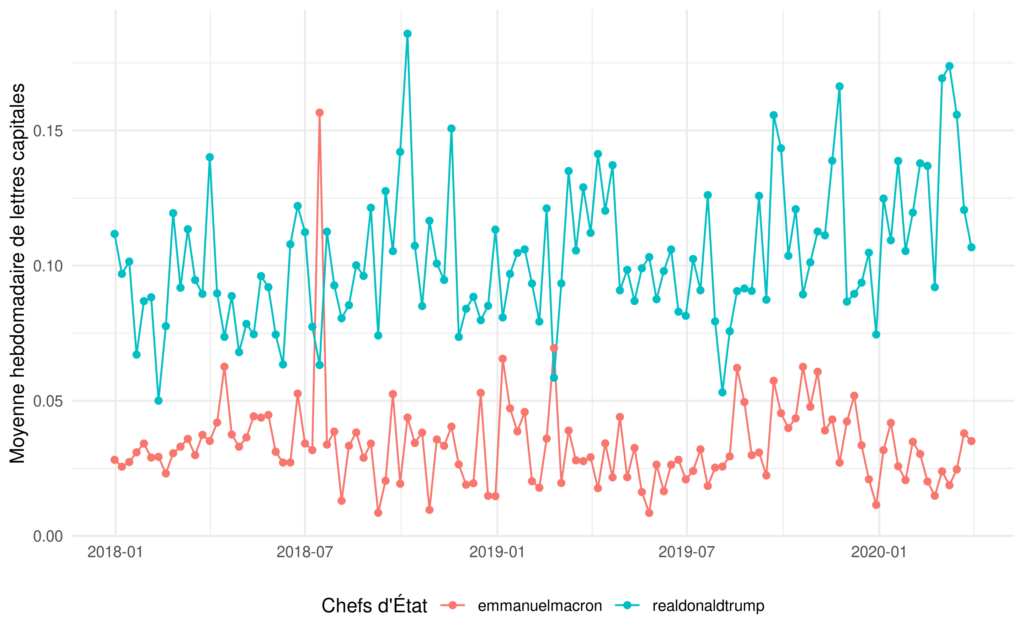
En basculant sur une moyenne hebdomadaire, la dichotomie est encore plus marquée.
Construction d’une modèle
Pour construire notre modèle, à partir de notre corpus text, nous créons un corpus train et un corpus test.
text <- text %>%
mutate(username = as.factor(username))
class(text$username)## [1] "factor"text_split <- initial_split(text, strata = username)
text_train <- training(text_split)
text_test <- testing(text_split)La fonction glm permet de créer un modèle linéaire généralisé. Notre modèle doit expliquer une variable donnée, en l’occurrence dans notre cas le nom d’un Chef d’État, par une ou plusieurs variables explicatives. Concernant les variables explicatives nous en utilisons deux :
- cap_dens : la densité de lettres capitales par publication ;
- cap_dens_weekly = la densité de lettres capitales hebdomadaires.
summary(model <- glm(username ~ cap_dens + cap_dens_weekly,
data = text_train,
family = "binomial"))##
## Call:
## glm(formula = username ~ cap_dens + cap_dens_weekly, family = "binomial",
## data = text_train)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -3.3545 -0.0071 0.0013 0.0279 2.3881
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -16.4926 0.7526 -21.913 <2e-16 ***
## cap_dens -0.9106 1.2603 -0.723 0.47
## cap_dens_weekly 269.9412 11.7950 22.886 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 10016.33 on 8593 degrees of freedom
## Residual deviance: 775.02 on 8591 degrees of freedom
## AIC: 781.02
##
## Number of Fisher Scoring iterations: 10En appliquant la fonction summary à notre modèle on constate que la variable explicative cap_dens_weekly a une p-value très faible ce qui donne à penser que cette variable joue un rôle important pour déterminer si une publication est davantage le fait de Donald Trump ou d’Emmanuel Macron.
text_test <- text_test %>%
mutate(pred = predict(model, ., type = "response"),
pred_username = if_else(pred >= 0.5, "Prédiction - Donald Trump", "Prédiction - Emmanuel Macron"))
text_test %>%
filter(!is.na(pred_username)) %>%
ggplot(aes(x = date, y = pred, color = pred_username)) +
geom_jitter() +
theme_minimal() +
labs(color = "Chefs d'État",
x = NULL,
y = NULL) +
theme(legend.position = "bottom")Le modèle étant créé, nous l’utilisons sur notre corpus test. De manière, quelque peu arbitraire et empirique, nous fixons un seuil à 0,5 pour convertir les probabilités issues du modèle en prédictions catégorielles. Évidemment, on pourrait ajuster la valeur t (threshold value) en fonction des erreurs et autres faux positifs engendrés par notre modèle.
| Prédiction – Donald Trump | Prédiction – Emmanuel Macron | |
|---|---|---|
| emmanuelmacron | 15 | 757 |
| realdonaldtrump | 2068 | 24 |
Pour évaluer la précision de notre modèle de classification basé sur l’analyse des lettres capitales, nous réalisons une matrice de confusion sur les données de notre corpus de test.
Il apparaît que ce dernier est relativement performant, avec 14 faux positifs pour Emmanuel Macron et 24 faux positifs pour Donald Trump.
L’analyse de la ponctuation et de la forme des lettres (majuscule, capitale et minuscule) constitue un axe intéressant pour mettre au jour des caractéristiques et des marqueurs identiaires sémantiques et linguistiques dans un corpus de texte.
Dans une logique de machine learning, on peut considérer que l’analyse de la forme des lettres, en complément d’une analyse de la ponctuation, de la tonalité ou encore des emojis, peut permettre de faire ressortir des patterns autres que des unités sémantiques, comme un mot ou groupe de mots (ngrams).
Dans certains contextes, on peut également considérer que l’utilisation synchronique de lettres capitales est un marqueur d’une forme de violence ou de colère à un moment donné, tandis qu’une utilisation diachronique renverrait, soit à une violence dans le temps, soit à une stratégie éditoriale spécifique faisant de l’utilisation accrue des lettres capitales un marqueur identitaire et communicationnel.
En nous intéressant à la communication de deux Chefs d’État, en l’occurrence Donald Trump et Emmanuel Macron, sur le réseau social Twitter on peut appréhender toute la fertilité heuristique des analyses de données basée sur la densité de lettres capitales.
tml_macron <- read_csv("https://www.dropbox.com/s/e9b9uzv6qckpyhg/macron.csv?raw=1")
tml_trump <- read_csv("https://www.dropbox.com/s/pwiyxdhl8klixro/trump.csv?raw=1")
join <- rbind(tml_macron,
tml_trump) %>%
group_by(username) %>%
filter(date >= "2018-01-01")Pour ce faire, nous avons récupéré l’ensemble des publications organiques de Donald Trump et d’Emmanuel Macron depuis le 1er janvier 2018.
obs <- join %>%
group_by(username) %>%
summarise(`Nombre d'observations` = n()) %>%
rename(`Chef d'État` = 1)Notre corpus de publications est composé des observations suivantes :
| Chef d’État | Nombre d’observations |
|---|---|
| emmanuelmacron | 3094 |
| realdonaldtrump | 8795 |
À partir de ces données, on peut calculer la densité de lettres capitales dans chacune des publications de Donald Trump et d’Emmanuel Macron.
Afin d’éviter tous biais, nous devons au préalable supprimer les mentions de comptes, ainsi que les URL :
text <- join %>%
rowwise() %>%
select(username, tweet, date) %>%
mutate(text_clean = gsub("@\\S+\\s*", " ", tweet),
text_clean = gsub("http\\S+\\s*", " ", text_clean),
text_clean = gsub("https\\S+\\s", " ", text_clean),
text_clean = gsub("pic.twitter.com/.*", " ", text_clean),
text_clean = gsub(".*pic.twitter.com", " ", text_clean),
nchar = nchar(text_clean),
nspaces = length(strsplit(text_clean, " ")[[1]]),
nchar_count = nchar - nspaces,
text_clean = paste0(tolower(substr(text_clean, 1, 1)), substr(text_clean, 2, nchar)),
text_clean = gsub("[[:punct:] ]", " ", text_clean),
cap_count = str_count(text_clean, "[A-Z]"),
cap_dens = cap_count / nchar_count,
week = round_date(date, unit = "week")) %>%
group_by(username, week) %>%
mutate(cap_dens_weekly = mean(na.omit(cap_dens))) %>%
ungroup() %>%
select(-c(nchar, nspaces)) %>%
filter(nchar_count > 0)
text %>%
ggplot(aes(x = date, y = cap_dens, color = username)) +
geom_jitter() +
theme_minimal() +
labs(color = "Chefs d'État",
x = NULL,
y = "Densité de lettres capitales / tweet") +
theme(legend.position = "bottom")En représentant graphiquement la densité de lettres capitales par publication de chacun des Chefs d’États dans le temps, on remarque qu’au-delà d’un certain seuil (0,35), et à une seule exception près, seules sont présentes les publications de Donald Trump.
Quant à celles d’Emmanuel Macron, pour l’essentiel, elles se situent en deçà du seuil des 0,25.
require(lubridate)
text %>%
mutate(date = floor_date(date, unit = "week")) %>%
group_by(username, date) %>%
mutate(moy = mean(cap_dens)) %>%
distinct(date, .keep_all = T) %>%
ggplot(aes(x = date, y = moy, color = username)) +
geom_line() +
geom_point() +
theme_minimal() +
labs(color = "Chefs d'État",
x = NULL,
y = "Moyenne hebdomadaire de lettres capitales") +
theme(legend.position = "bottom")En basculant sur une moyenne hebdomadaire, la dichotomie est encore plus marquée.
Construction d’une modèle
Pour construire notre modèle, à partir de notre corpus text, nous créons un corpus train et un corpus test.
text <- text %>%
mutate(username = as.factor(username))
class(text$username)## [1] "factor"text_split <- initial_split(text, strata = username)
text_train <- training(text_split)
text_test <- testing(text_split)La fonction glm permet de créer un modèle linéaire généralisé. Notre modèle doit expliquer une variable donnée, en l’occurrence dans notre cas le nom d’un Chef d’État, par une ou plusieurs variables explicatives. Concernant les variables explicatives nous en utilisons deux :
- cap_dens : la densité de lettres capitales par publication ;
- cap_dens_weekly = la densité de lettres capitales hebdomadaires.
summary(model <- glm(username ~ cap_dens + cap_dens_weekly,
data = text_train,
family = "binomial"))##
## Call:
## glm(formula = username ~ cap_dens + cap_dens_weekly, family = "binomial",
## data = text_train)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -3.3545 -0.0071 0.0013 0.0279 2.3881
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -16.4926 0.7526 -21.913 <2e-16 ***
## cap_dens -0.9106 1.2603 -0.723 0.47
## cap_dens_weekly 269.9412 11.7950 22.886 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 10016.33 on 8593 degrees of freedom
## Residual deviance: 775.02 on 8591 degrees of freedom
## AIC: 781.02
##
## Number of Fisher Scoring iterations: 10En appliquant la fonction summary à notre modèle on constate que la variable explicative cap_dens_weekly a une p-value très faible ce qui donne à penser que cette variable joue un rôle important pour déterminer si une publication est davantage le fait de Donald Trump ou d’Emmanuel Macron.
text_test <- text_test %>%
mutate(pred = predict(model, ., type = "response"),
pred_username = if_else(pred >= 0.5, "Prédiction - Donald Trump", "Prédiction - Emmanuel Macron"))
text_test %>%
filter(!is.na(pred_username)) %>%
ggplot(aes(x = date, y = pred, color = pred_username)) +
geom_jitter() +
theme_minimal() +
labs(color = "Chefs d'État",
x = NULL,
y = NULL) +
theme(legend.position = "bottom")Le modèle étant créé, nous l’utilisons sur notre corpus test. De manière, quelque peu arbitraire et empirique, nous fixons un seuil à 0,5 pour convertir les probabilités issues du modèle en prédictions catégorielles. Évidemment, on pourrait ajuster la valeur t (threshold value) en fonction des erreurs et autres faux positifs engendrés par notre modèle.
| Prédiction – Donald Trump | Prédiction – Emmanuel Macron | |
|---|---|---|
| emmanuelmacron | 15 | 757 |
| realdonaldtrump | 2068 | 24 |
Pour évaluer la précision de notre modèle de classification basé sur l’analyse des lettres capitales, nous réalisons une matrice de confusion sur les données de notre corpus de test.
Il apparaît que ce dernier est relativement performant, avec 14 faux positifs pour Emmanuel Macron et 24 faux positifs pour Donald Trump.

Nous avons un quart de siècle de recul à la fois pour mesurer l’efficacité d’une intention et juger de sa cohérence. Ce qui pourrait se formuler ainsi : comment a-t-on « scientifiquement » défini la valeur universelle pour en faire une catégorie juridique ? Plus malicieusement : comment des représentants d’États ont-ils parlé au nom de l’humanité ou des générations futures et oublié leurs intérêts nationaux ou leurs revendications identitaires ? Plus médiologiquement : comment une organisation matérialisée (le Comité qui établit la liste, des ONG, des experts qui le conseillent…) a-t-elle transformé une croyance générale en fait pratique ? Comment est-on passé de l’hyperbole au règlement ? De l’idéal à la subvention ?

En venant briser la réputation et l’autorité d’un candidat, en venant saper les fondements du discours officiel et légitime d’un État, les fake news et autres logiques de désinformation, viennent mettre au jour l’idée d’un espace public souverain potentiellement sous influence d’acteurs exogènes.

Nos sociétés de l'information exaltent volontiers la transparence. En politique, elle doit favoriser la gouvernance : plus d'ententes clandestines, de manoeuvres antidémocratiques obscures, d'intérêts occultes, de crimes enfouis. En économie, on voit en elle une garantie contre les défauts cachés, les erreurs et les tricheries, donc un facteur de sécurité et de progrès. Et, moralement, la transparence semble garantir la confiance entre ceux qui n'ont rien à se reprocher. Dans ces conditions, il est difficile de plaider pour le secret. Ou au moins pour sa persistance, voire sa croissance. Et pourtant...

L’image de citadelle assiégée renvoyée par Madrid au moment de la crise catalane soulève de nombreuses questions, et interroge sur la propension que peuvent avoir certains acteurs politiques à tendre vers des logiques d’exception au nom d’une lutte contre une menace informationnelle et/ou pour défendre un système démocratique en proie à de prétendues attaques exogènes.


